Uncovering the Corpus
500,000 entries, 2,000,000 data points
If you have not(yet) been able to find the corpus, here’s a helpful link with over 500,000 entries and 1.4 GB worth of text files to plough through, this dataset is indeed quite a behemoth to wrangle. In its raw form, you would need to create some command line loops to extract each file. This process may take a while, ideally you would like to also store this as a .json or .csv for future use as he file size is slightly smaller, about 30% it seems.
Anatomy of an Email.
An Email comprises of several components.
- From
- To
- Cc
- Bcc
- Subject
- Body
- Date
However, it is worth noting that in a closed loop (where all participants are accounted for), there really are just 5 items. From, Subject, Body, Date, User. This is because for any message, 2 messages are created. One on part of the outbox, the other, inbox. We have applied this concept to our processing and have extracted the 4 and included the direction of the message (received/sent)
Hello Regex.
In my years as a data analyst, regex has never been so in demand yet easily dismissed. When it comes to languages people simply dismiss it on grounds of complexity or high level knowledge - to which I can now safely say, no. Understanding regex allows for significant enhancements to your NLP experiments and refinement to simplistic if/else statements when it comes to legacy programs. I would recommend trying out your expressions online. As they say practice makes perfect and soon you’ll be able to handle any form of regex from words, to emails and even code (which you would need to some extent in this exercise.)
Sculpting.
Data cleaning is such a prerogative term. Yes, while we are cleansing it, we are also showing data as it ‘should be’. To that end, isn’t sculpting more appropriate?
Opinions aside, working through pre-processing requires a number of iterations and reviewing results, there is no easy way around this and revisiting even at the pre-processing stage is just as likely to occur when we are building our models. In my view only through experience over time or an in depth knowledge of the datasets can we mitigate this exercise. This link provides some insight into dealing with issues but I personally felt that some are a little convoluted and have instead broken them down into issues for each component
Subject issues
- No subject
- Emails
Body issues
- Hyperlinks & Websites
- Subject lines
- Image references
- Page/Line breaks
- Timings
- Documents (.xls, .doc, .pdf)
- Emails less than 4 words, and from 1000 words
- Discard as these are not meaningful
- Infrequent senders (less than 3 messages)
- Discard as these people would not add meaningful results
- Email signatures
- Discard as these are independent of topics.
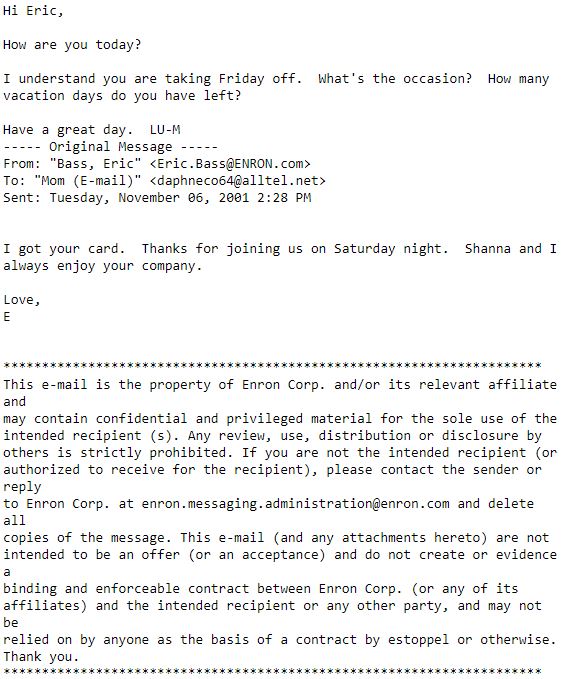
User issues
- Users may have multiple email addresses While this is not a data issue per se, it is an issue to be addressed later.
Final Results
Before we get into the results of what it should look like, I would like to add that the act of reviewing data is sometimes rewarding not just from understanding the data given but also, sometimes.. you do find really interesting emails. clean jokes, dirty jokes, and even acts of possible infidelity
But lets not get distracted. For purposes of performing our topic modelling, we would drop duplicate emails
We would save the result after cleansing, and this is how it should look: