Topic Modelling (LDA & NMF)
What is in a topic?
Topic modelling is the task of identifying topics through semantic text structure that describes a set of documents. Each method described below relies on different ideas on how topics are deduced or understood.
Terminology Alert!
LDA
Short for Latent Diriclet Allocation, the word ‘Latent’ is used as topics will only emerge during the modelling process. Paper Here.
How does it work? To quote the paper:
The basic idea is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words.”
The concept is intuitive, if I were to talk about things such as market capitalization, relative valuation, share price, earnings. Probably a discussion on equity valuation, or equity. Conversely, if it were to be risk free rate, maturity period, par value. Probably a discussion along the lines of fixed income assets. Even for somewhat similar topics we can observe with some clarity the different topics arising from key words. Of course, as with most machine interpreted results, this is a probability, in the given example, it could be a particular bond that was issued by the company in which it is likely to default on. Determining the specific topic, would then be tricky as both topics are equally likely with no necessary dominant singular topic.
How to use it Using LDA is simple - once we have done the arduous task of preprocessing, machine learning algorithms are generally easy to apply*. *results may vary, and can take a really long time depending on volume.
There are 3 main components for LDA, as narrated by the pound(#) key.
# Create Dictionary
id2word = corpora.Dictionary(spacy_text)
# Create Corpus
texts = spacy_text
# Term Document Frequency
TDF = [id2word.doc2bow(text) for text in texts]
Dictionary, Corpus, and Term frequency.
Dictionary is the vector space in which the machine is able to look up to understand its meaning.
Corpus are all the documents in which we would like to perform our analysis on.
Term Document Frequency, are the vectors that exist in the dictionary. This allows the system to understand the frequency of words as a whole and within each document. As such, LDA uses a CountVectorizer type BOW method to deduce topical representations.
NMF
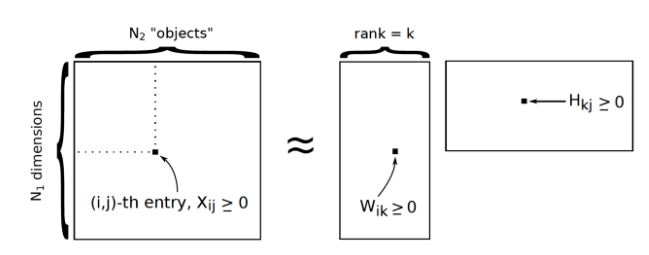
Short for Non-Negative Matrix Factorization, a type of Single Vector Decomposition technique.
How does it work?
Similar to the concept of Principal component analysis (PCA), NMF transforms coefficients into a lower dimension. Through this lowered dimension it reconstructs a N*M matrix which are the topics to approximate the input dataset.
How to use it
I have chosen to use this method for topic modelling due to the use of TF-IDF Vectorizer in which common terms are penalized. This is preferable to the countvec method we have applied with LDA as it minimizes the issue of frequently occurring words that do not yield any value to analysis, also known as: you probably forgot some stop words.
The process itself is also simple once the vectors have been created. NMF can be applied from sklearn.decomposition library.
Decision time.
As with all models, how do we decide which to use? Regression can be entertained by r^2 or RMSE scores; Classification with the confusion matrix.
Further reading shows there is a score particularly for the analysis of topic modelling, this score is the coherence score and it strives to quantify the interpretability of results through the ‘spread’ of words in the vector space. For purposes of our analysis we have used the extrinsic model aka UCI Details here.
Of course, these scores are dependent on the number of topics that we have selected and as it is dependent on the corpus, more topics could result in better coherence, or worse. a plot is needed to further understand the impact of selecting ‘k’ topics. The results of our NMF coherence scores calculated are represented in the graph below.

p.s. there is also a perplexity score, which I have computed but did not find it as meaningful when it came to topical interpretation.
Result
For the most the modelling is done and we have coherence scores to show which is the ‘better’ model. I have chosen coherence as the measure to define success as it allows us to better interpret the topics and identify topical trends over time. As a result our LDA model provides a better UCI coherence at 0.551 compared to the best UCI for NMF of 0.23. The illustration below using pyLDAvis demonstrates a good separation of topics. I have seletced topics 3 and 4 to show below.
Our final topic list is as follows:
topic_dict_lda3={0:'office communications',
1:'industry expertise',
2:'social',
3:'operational compliance',
4:'trading',
5:'legal',
6:'spam & html communique'
}
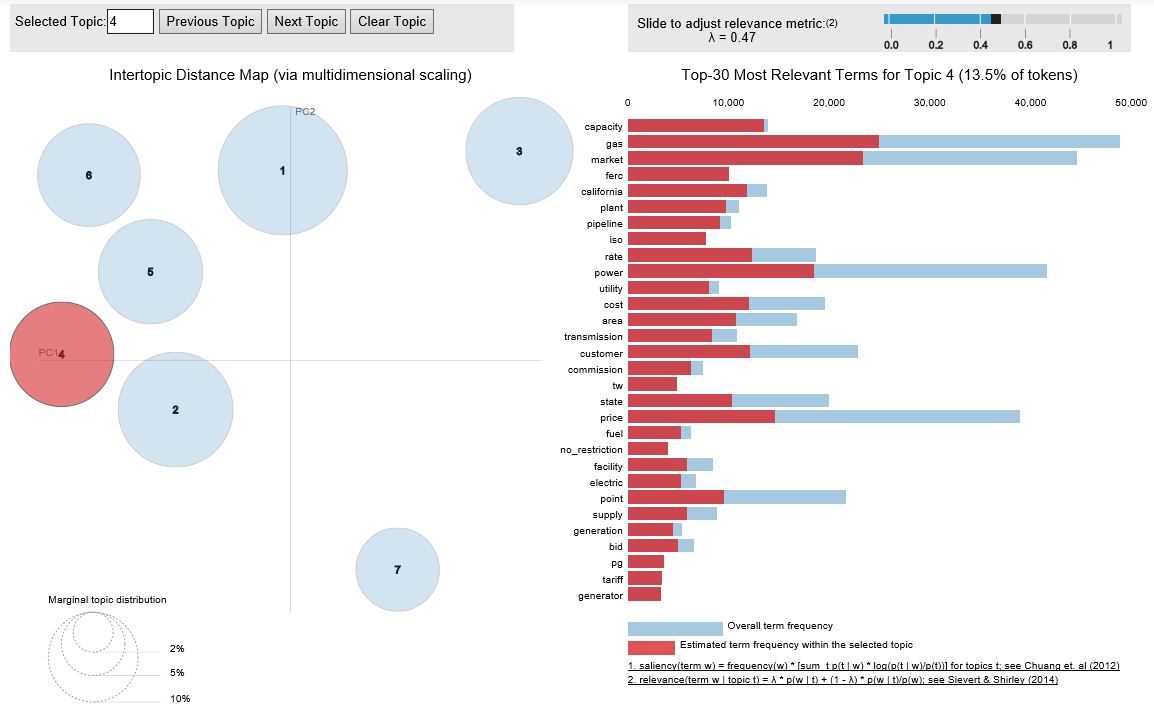 Above is mainly on the topic of operational compliance with words such as FERC (federal energy regulatory commission) price, rates and the California crisis in the early 2000s
Above is mainly on the topic of operational compliance with words such as FERC (federal energy regulatory commission) price, rates and the California crisis in the early 2000s
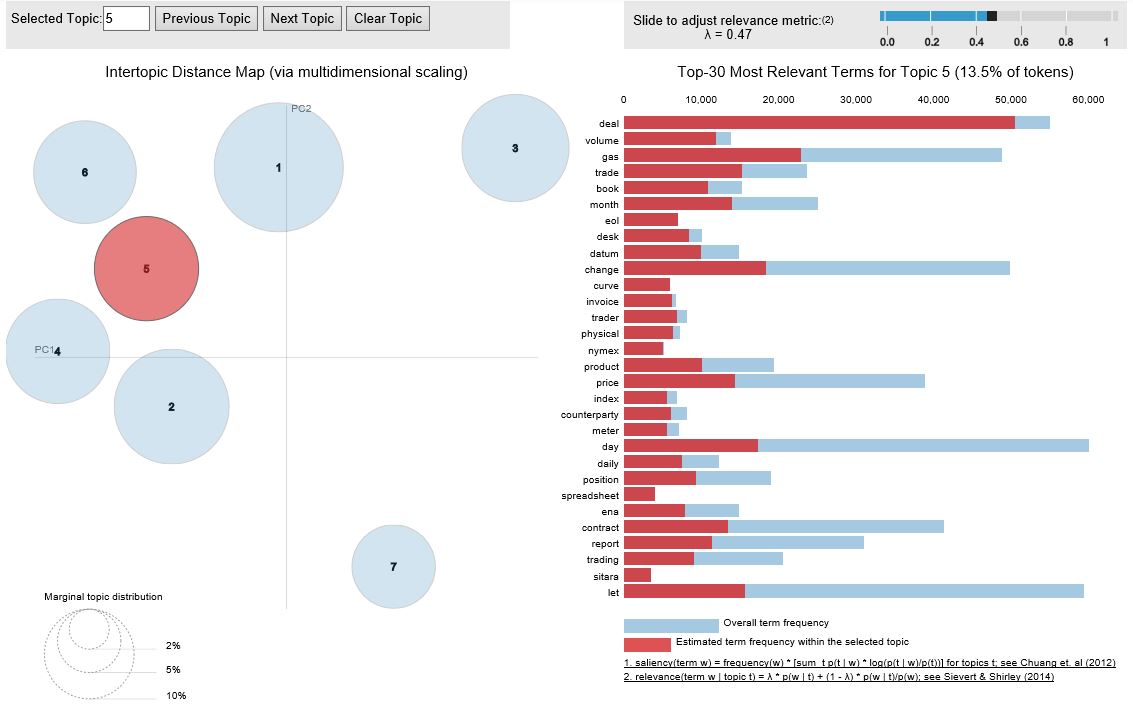 Above is mainly on the topic of trading with words such as deal, volume, trade, book, NYMEX (New York mercantile exchange)
Above is mainly on the topic of trading with words such as deal, volume, trade, book, NYMEX (New York mercantile exchange)