Hello World
Foreword
If you’re on this page, chances are you’re here on introduction.. or you’ve been trawling github. This blog/repo was created for a project done during my course with General Assembly and may see further future enhancements, time permitting. Overall, this project is meant to be a proof of concept, utilizing NLP, Network analysis, and simple dashboarding to illustrate insights that can be achieved with a simplistic layer of machine learning on what is otherwise an data retrieval process.
Before we get into further detail, as we have much to cover and it is not practical to go through everything in a single sitting, I would be going through this project in 5 sections/posts.
- Data Cleansing and sourcing
- NLP techniques
- Topic Attribution
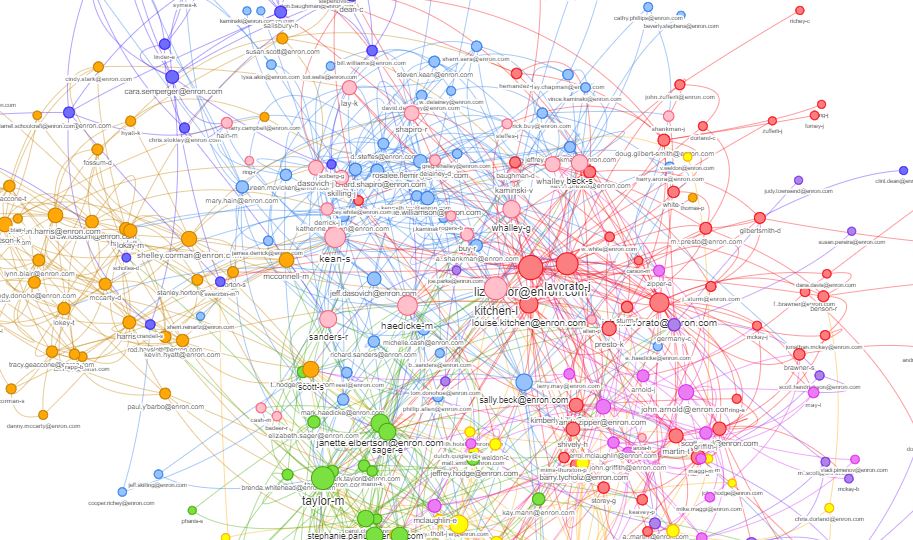
- Community Detection
- Dashboarding and Stats extraction.
Background
The Enron scandal is probably one of the most defining events in the world of accountancy, birthing to the Sarbanes-Oxley Act. The concept of ‘mark to market’ and valuation still haunts even till today (reprised by the subprime crisis of 08’). Being in the accounting field for over half a decade, data science presents an interesting opportunity to answer the question - are we able to anticipate bad actors or trends? This project aspires to provide a level of thought in the field that is beyond MS Excel and beyond conceptual application of CAATs (Computer Assisted Audit Techniques)
Problem Statement
Due to higher level priorities or due to the pace in which their businesses move today business owners rely significantly on word of mouth or time intensive meetings, just to keep the pulse on the business. A single bad actor and its influence can spark a downward spiral or decay of product & value. Identifying key issues as it appears and tracking knowledge dependencies can help reduce confusion both from a resource allocation perspective and issue diagnosis.
Objective
There are 3 main objectives of this project:
Using NLP techniques such as Non-Negative Matrix Factorization (NMF) and Latent Dirichlet Allocation LDA) this project would:
1) Identify key topics
2) Attribute topics to messages exchanged in the corpus
Using Network Graphs:
1) Identify Degree of each User
2) Identify networks that exist using Louvain algorithm.
Once the above has been identified and attributed:
1) Examine topic use over time, by user/email address
2) Identify any topical significance of each employee position type.